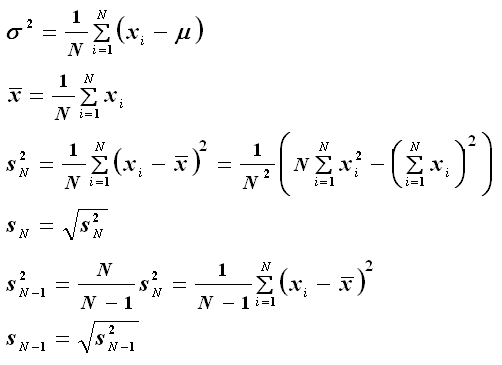The terms "sample" and "population" are inconsistent across sources so be
careful! This is because it is not always clear if your "sample"
represents the entire "population" of random values, or is truly just a
"sample" of a larger "population".
In most cases, one wishes to estimate the properties of a large population
based on a subset of samples. Usually in this case, the actual mean of
the population, μ, is not known and
must be estimated from the sample as the sample mean, x.
This may seem like a small point, but causes problems when trying to estimate
the variance of the population given a small sample. It turns out from
k-statistics that the best estimate for the population variance is N/(N-1)
times the sample variance. So, you would want to use the "N-1" values
listed above. If, on the other hand, your list includes the entire
population, then you would probably want to use the "N" values. If you have a large number of samples then
this difference is trivial. Note again that several sources invert the
meanings of "population variance" and "sample variance".
In Excel, the STDEVA function gives sN-1
while STDEVP gives sN.
(The "P" at the end of STDEVP is for "population" and highlights some of the
terminology problems).
You can also use the range, R, of a sample to estimate the standard
deviation using order statistics.